

Memory Beyond Vectors: Why Autonomous Agents Need GraphRAG
Vector databases give your agents amnesia for relationships. It’s time to add structure to the stack.

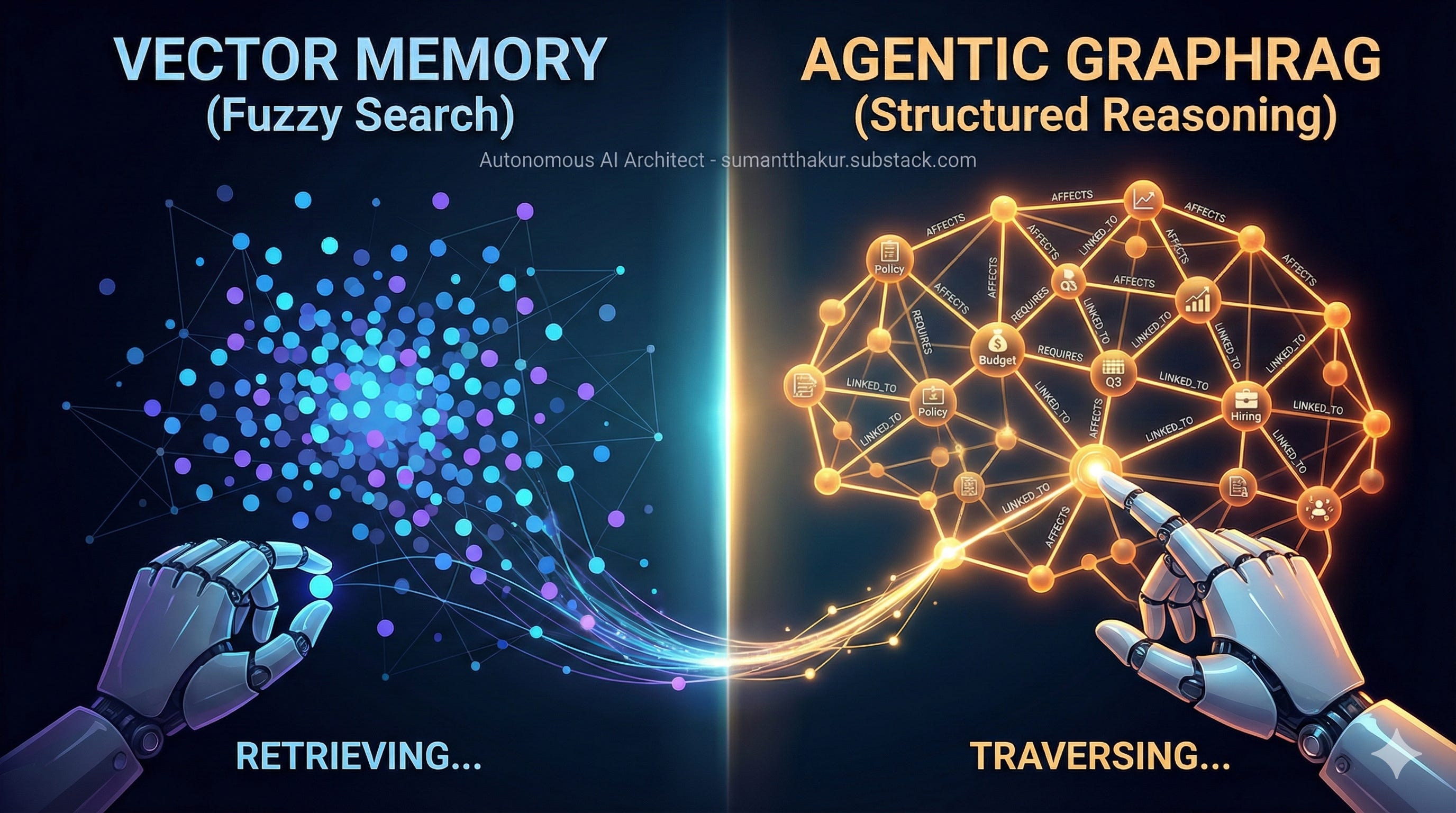
If you built a RAG system in the last two years, the architecture was probably predictable: chunk your data, embed it using OpenAI or Cohere, store it in Pinecone, Weaviate, or Qdrant, and retrieve with cosine similarity.
For simple Q&A, this works surprisingly well.
But as we move from chatbots to autonomous agents: systems expected to reason, plan, and act across tools and organizational context the cracks are starting to show.
Ask a vector-based agent:
“How does the Q3 privacy policy change affect our Q4 engineering hiring budget?”
A vector database will likely return chunks mentioning privacy policy, Q3, hiring, and budget. What it will not recover is the invisible chain of relationships connecting those concepts. The agent sees similarity, not structure. It retrieves fragments, not causality.
This is the core limitation of vector-only memory and why agents need something more.
The hidden problem: vector amnesia
Vector databases are often described as “semantic search on steroids.” That description is accurate and incomplete.
Vectors are exceptional at answering questions like:
“What does this document talk about?”
“Which paragraph is most similar to this question?”
“Where is this concept explained?”
They struggle when the question is:
“What changed because of X?”
“Which decision depends on Y?”
“How does policy A indirectly affect system B?”
Why?
Because vectors flatten context.
When you chunk a document, you sever relationships. If Project Alpha is described in one chunk and its budget constraint appears three pages later, a vector retriever may fetch one without the other or fetch both without understanding the link between them.
Autonomous agents don’t just retrieve facts. They need to traverse relationships:
Policy → Compliance requirement
Compliance → Deployment gate
Deployment gate → Release delay
Release delay → Revenue impact
That is not a similarity problem. It’s a graph problem.
From similarity to structure
To reason about systems, agents need explicit representations of:
Entities (projects, policies, people, services, metrics)
Relationships (AFFECTS, DEPENDS_ON, BLOCKS, OWNS)
Directionality and scope (who impacts whom, and how far)
This is exactly what knowledge graphs are designed to encode.
GraphRAG is the architectural pattern that combines:
the fuzzy recall of vector search, with
the structural precision of graph traversal
The result is memory that supports multi-hop reasoning, not just retrieval.
What GraphRAG actually is
GraphRAG does not mean replacing your vector database.
It means adding a structured memory layer derived from the same documents your vector store already indexes.
At a high level:
Documents are ingested as usual for vector search.
An LLM extractor also processes those documents to identify:
Entities
Relationships
Attributes (dates, numbers, constraints)
That structured data is stored in a graph database.
At query time, the agent dynamically decides how to retrieve information:
vectors, graph traversal, or both.
This pattern has been popularized by Microsoft’s GraphRAG work and is now emerging as a de-facto standard for agentic systems.
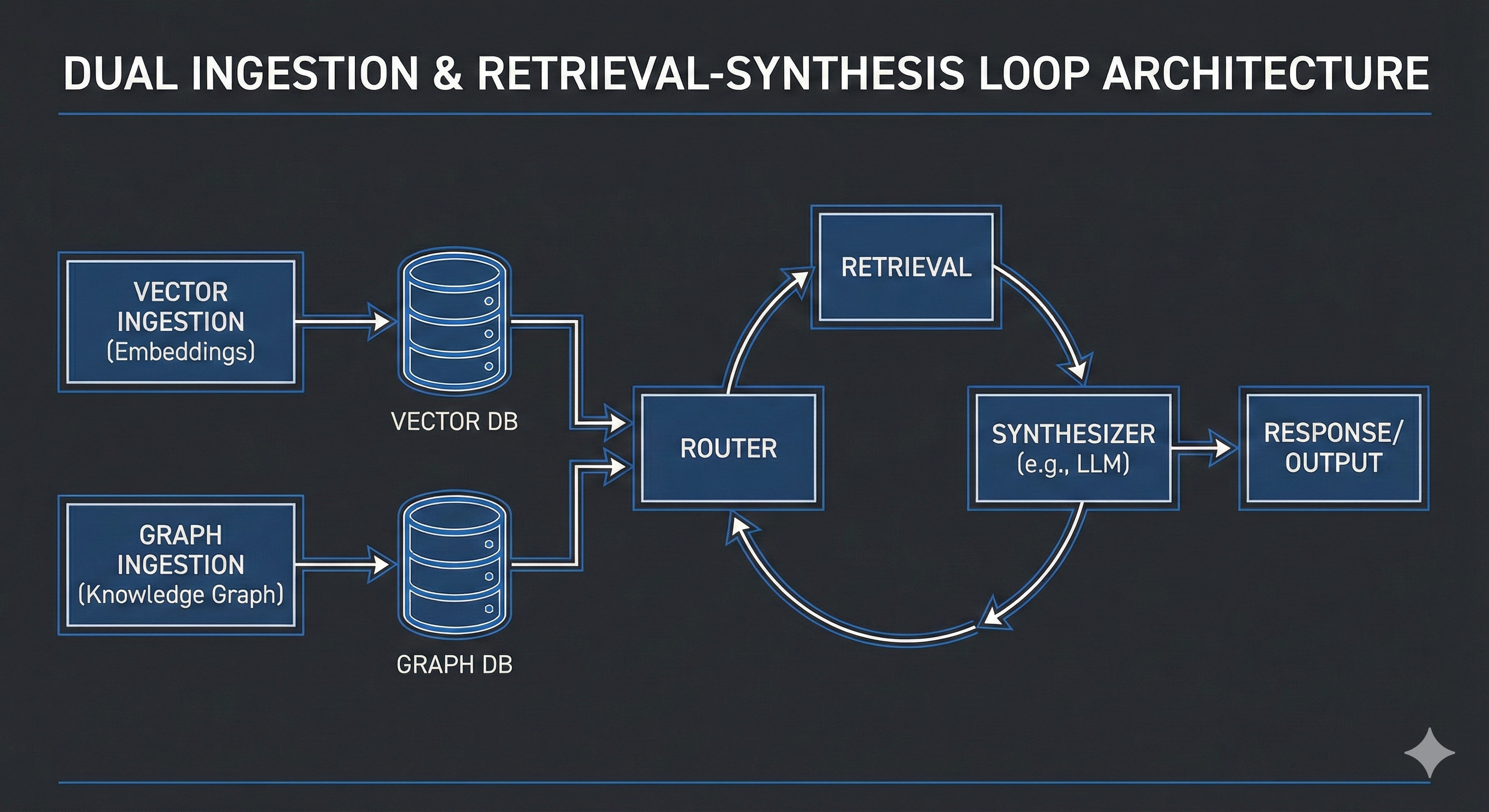
The ingestion pipeline: where the real work happens
Most people underestimate ingestion and over-optimize retrieval. In GraphRAG, ingestion is where correctness is won or lost.
1. Unstructured path
This is your existing RAG pipeline:
Chunk text
Embed
Store in a vector database
You still need this for:
fast recall
paraphrase matching
grounding answers in raw text
2. Structured path
Here, an Extractor Agent processes documents to produce structured outputs:
Entities: Person, Org, Project, Policy, Service, Metric
Relationships: AFFECTS, DEPENDS_ON, AUTHORED_BY, REPLACES
Attributes: dates, budgets, thresholds, confidence
These are written into a graph database such as Neo4j or Memgraph.
This graph is derived, not authoritative. It is a reasoning aid, not a source of truth.
The unavoidable pain: entity resolution
If one document says “J. Smith” and another says “John Smith,” your graph will happily create two nodes and your agent will reason incorrectly.
Entity resolution is the hardest part of GraphRAG.
In practice, teams use:
deterministic rules (IDs, emails, file paths)
embedding similarity for alias detection
an LLM reconciliation pass for ambiguous cases
confidence scores and human review for high-impact nodes
There is no shortcut here. If your graph is wrong, your agent will be confidently wrong.
Retrieval is no longer just top-k
In vector RAG, retrieval is a single operation: top_k.
In GraphRAG, retrieval is a loop.
Step 1: Route the query
The agent first decides how to think:
simple fact → vector retrieval
causal / multi-hop → graph traversal
mixed → hybrid
This router can be heuristic-based or LLM-based.
Step 2: Graph traversal
For relationship-heavy queries, the agent:
identifies start nodes
explores neighbors (1–3 hops)
optionally uses community detection (Leiden/Louvain) to find coherent subgraphs for summarization
Community detection helps answer questions like:
“What are the major themes or impact areas related to this policy?”
Step 3: Vector grounding
Nodes in the subgraph link back to source documents. The agent performs vector search within that constrained context to pull precise evidence.
Step 4: Synthesis
The LLM combines:
structured relationships (the graph)
unstructured evidence (text chunks)
into a single answer with provenance.
A walkthrough
Question:
“How will the Q3 privacy policy change affect our Q4 engineering hiring?”
Graph contains:
{PrivacyPolicy_Q3}{RevenueForecast_Q3}{HiringPlan_Q4}
Edges:
PrivacyPolicy_Q3 —[AFFECTS]→ RevenueForecast_Q3RevenueForecast_Q3 —[CONSTRAINS]→ HiringPlan_Q4
Agent steps:
Router classifies as multi-hop reasoning.
Graph traversal retrieves the causal chain.
Vector search pulls numeric assumptions and explanations.
LLM synthesizes:
“The Q3 privacy policy reduces projected revenue by ~8% (Finance Report v3), which lowers the available hiring budget and reduces planned Q4 engineering hires from 12 to 8 (Hiring Plan v2).”
This answer is explainable, traceable, and actionable.
Agentic orchestration
GraphRAG works best when the graph is treated as a tool, not a static database.
A typical agent loop:
Router Node
Graph Query Generator
Execution + Validation
Retry / Correction
Synthesis
Frameworks like LangGraph make this explicit and manageable. The key shift is mental: retrieval becomes stateful reasoning, not a single function call.
Trade-offs you should not ignore
GraphRAG is powerful and expensive.
Latency: graph traversal is slower than vector search. Use it for System-2 agents, not autocomplete.
Cost: extraction requires significant LLM usage. Batch, cache, and prioritize high-value documents.
Complexity: debugging graphs is harder than debugging embeddings.
Maintenance: entity resolution and schema evolution are ongoing work.
If your use case is simple Q&A, vectors are enough. GraphRAG earns its keep only when reasoning depth matters.
When GraphRAG is worth it
GraphRAG shines in environments with:
policy and compliance
finance and forecasting
platform engineering and infra dependencies
large codebases with ownership and impact analysis
In short: enterprise reality.
Final takeaway
Vectors are excellent at finding needles in haystacks.
Knowledge graphs explain how the needles are connected and why they matter.
If you’re building autonomous agents expected to reason across systems, documents, and decisions, vector-only memory will eventually fail you. GraphRAG is the practical path forward: not hype, not replacement but augmentation.
Build the map, not just the coordinates.
Much a wonderfully written, easy to understand article. Thanks Sumant
Amazing article, Sumant! thank you!