

Shift Left, Then Stack Deep: Building Reliable AI-Generated Infrastructure

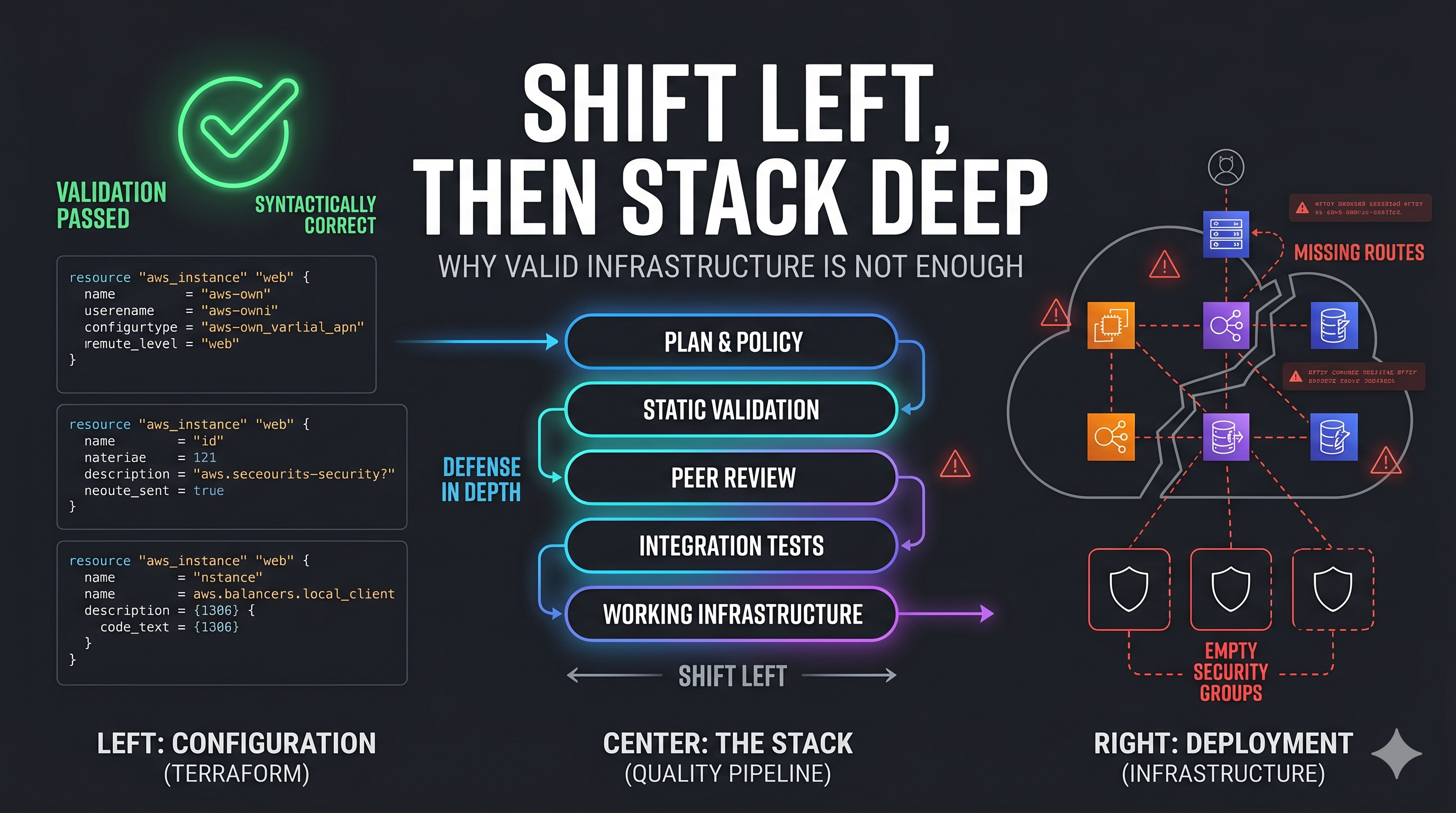
terraform validate is lying to you.
That sounds dramatic, but it is exactly what we found.
`We generated a Terraform configuration that passed validation with zero errors. It looked correct. It parsed. It type-checked. It satisfied the schema. And it still produced infrastructure that was functionally broken.
That is the gap we had to solve.
It is not enough for AI-generated infrastructure to be syntactically valid. It has to be operationally correct. It has to work in the real world, not just pass a checker.
And that distinction changes everything.
The gap between valid and working
Everyone reaches for terraform validate first. It is the obvious safety net. It checks syntax, required attributes, and type constraints. If it passes, the configuration is “correct.”
Except it often is not.
Here is what a generated config can pass validation with and still get wrong:
Route tables exist, but no routes are attached.
Security groups are created, but they have no ingress or egress rules.
ECS services point to a variable reference instead of the local task definition resource.
IAM roles exist, but no permission attachments are wired in.
Log groups referenced by task definitions do not exist.
Every one of those errors is invisible to terraform validate.
Every one of those errors can break deployment.
That is the dangerous part: the code looks right until you try to use it.
The whack-a-mole trap
Our first instinct was the obvious one: fix the output.
If the LLM generates bad HCL, fix the HCL.
So we started adding deterministic repair logic. Regex fixes. Type inference. Variable generation. Attribute deduplication. File merging rules. Batch-level composition logic.
It worked, but only in the narrow sense that each fix solved the exact case it was written for.
Then the edge cases started multiplying.
A regex that fixed interpolation syntax did not handle heredocs.
A variable inference rule guessed a type from a name and got it wrong.
A merge pass that worked for one file type broke another.
A deduplication rule fixed one class of duplicates and created another.
The codebase got bigger. The maintenance burden got heavier. The quality improved slowly, but not fast enough.
We were playing whack-a-mole.
That is when it became clear that fixing generated code was the wrong place to spend most of our energy.
The shift-left insight
The breakthrough came when we stopped staring at the generated HCL and started staring at the plan.
That is where the real problem was hiding.
Our pipeline has two main stages. First, a planner agent decides what resources should exist, how they depend on each other, and how they should be grouped into batches. Then a composition agent turns each batch into HCL.
The planner had a dependency expander that inferred obvious links from schema attributes. If a resource had a vpc_id field, it probably depended on a VPC. That part worked.
But it only caught explicit references.
It did not know that:
a route table is useless without actual routes
a security group is useless without rules
an ECS task definition needs a log group
an IAM role needs policy attachments
So the planner left out companion resources. The composition agent faithfully generated code for an incomplete plan. The result was valid Terraform that still could not work.
That was the lesson.
The problem was not code generation.
The problem was planning.
Fixing the plan is cheap. Fixing the code is expensive.
This is the real shift-left principle for AI-generated infrastructure.
If the plan is wrong, adding a missing resource is trivial. It is just a JSON append.
If the code is wrong, now you need a repair step that has to:
read the full context
generate a valid resource block
wire it correctly into the rest of the graph
place it in the right file
re-run validation
make sure nothing else broke
That is expensive.
That is why the best place to catch mistakes is as early as possible.
The earlier you catch a missing resource, the cheaper it is to fix.
The earlier you catch an invalid dependency, the less damage it does.
The earlier you force completeness, the less repair work you need downstream.
That is the real meaning of shift left in an LLM pipeline.
Defense in depth: stack quality, do not trust one layer
Of course, shifting left is not enough on its own.
LLMs are probabilistic. They will always find new ways to produce unexpected output. That means one guardrail is never enough. The answer is defense in depth: multiple quality layers, each catching what the previous one missed.
That is the architecture we ended up with.
Layer 1: knowledge at generation time
The composition agent has access to curated provider skills and to a registry documentation tool that can fetch attribute-level details when needed.
That matters because schema JSON is often too bare. In practice, the raw schema tells you the shape of the resource, but not enough about how attributes interact. The docs fill that gap.
This is the cheapest quality layer.
If the model knows the right constraint before it generates the code, no repair is needed later.
Layer 2: plan completeness review
Before generating HCL, the plan itself gets reviewed for functional completeness.
The review step checks things like:
Does every route table have actual routes?
Does every security group have rules?
Does every IAM role have policy attachments?
Are all user requirements covered by planned resources?
If the plan is incomplete, it is augmented before composition starts.
That is the important part: the system does not wait until the code is wrong to realize the plan was incomplete.
Layer 3: Terraform validate + repair loop
This is the standard mechanical guardrail.
terraform validate catches syntax issues, type mismatches, and missing required attributes. When it fails, the repair agent reads the error and rewrites the broken blocks.
This loop catches the mechanical mistakes that still make it through composition.
It does not solve completeness.
It solves correctness.
Those are different problems.
Layer 4: contextual code review
After validation passes, the generated files are reviewed as a whole.
That matters because many problems are semantic, not syntactic.
You can have:
a valid configuration with the wrong wiring
a complete-looking set of files with missing relationships
resources that exist but do nothing useful
file-level correctness that still fails at system level
The holistic review catches the issues that syntax validation cannot see.
Layer 5: evaluation over time
The final layer is measurement.
This is the part most teams skip.
You do not just want the pipeline to feel better. You want to know whether it is actually better.
That means tracking things like:
how often companion resources are missing
how often validation fails
how many repair loops are needed
how completeness scores change over time
whether the plan review layer is actually reducing downstream errors
If you cannot measure that, you are just hoping the system got better.
What each layer catches
No single layer solves the problem.
Each one catches a different class of failure.
Registry docs catch attribute-level constraints and conflicts.
Plan review catches missing companion resources and incomplete coverage.
terraform validatecatches syntax and type errors.Repair loops catch mechanical mistakes.
Holistic code review catches wrong wiring and semantic gaps.
That is the point of stacking layers.
Every layer fails differently.
So we stack them.
The general principle
This pattern applies to any LLM code generation pipeline, not just Terraform.
If we were to generalize the lesson, it would look like this:
Give the model current knowledge. Do not rely on stale training data for important API details.
Review the plan before generating code. Catch incompleteness early.
Validate mechanically first. Use the native tooling before asking an LLM to judge the output.
Review holistically after generation. Cross-file issues do not show up in isolated checks.
Measure quality over time. If you cannot chart the improvement, you do not know whether the system is actually getting better.
That is the real playbook.
Not smarter prompts.
Not larger outputs.
Better sequencing.
Where this goes next
We are still iterating.
The plan review layer catches most of the obvious companion-resource gaps. But there is a deeper question underneath all of this: should review itself stay LLM-based, or should we move toward deterministic graph analysis of the resource plan?
The LLM approach is flexible. It can adapt to new resource types without code changes.
The deterministic approach is more reliable. It does not hallucinate. But it requires maintaining a rules layer.
That is the tradeoff.
For now, the defense-in-depth stack gives us the best of both worlds:
deterministic validation where we can use it
LLM judgment where we need it
measurement so we know what is actually helping
The real lesson
This project taught us something simple but important:
In AI-generated infrastructure, the bar is not “does it validate?”
The bar is not even “does it deploy?”
The real bar is:
Can the system consistently produce infrastructure that survives reality?
That is the difference between generated code and working systems.
And that is why the plan matters more than the code, the early checks matter more than the late repairs, and defense in depth matters more than any single clever fix.
Flurit is what I’m building to make agentic DevOps safe by design where identity, policy, and execution boundaries are first-class, not afterthoughts.
awesome read. 100% on the defense in depth points listed here.