

The Workflow Illusion: Why Agent Frameworks Are Not Control Planes
Agent frameworks solve execution. Production systems still need control

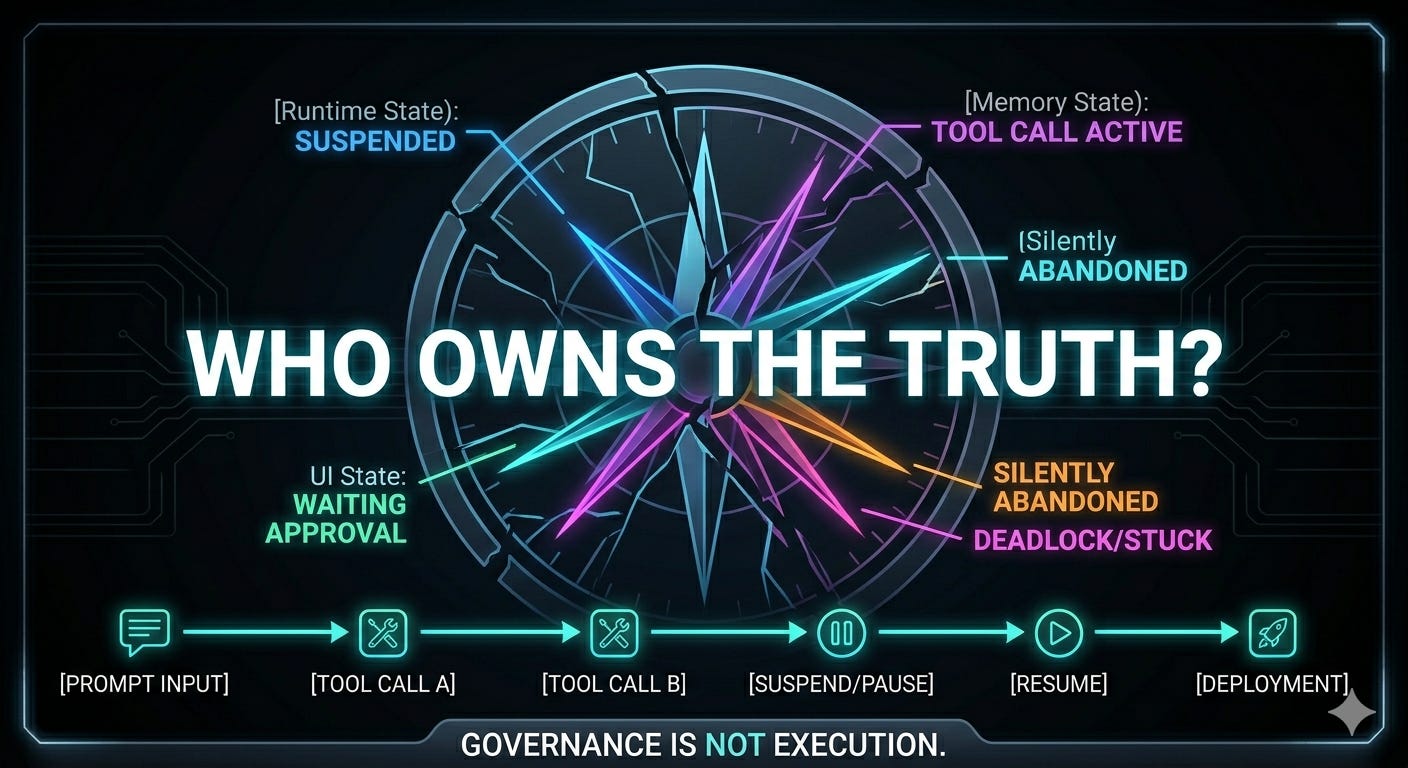
Here’s the illusion at the center of modern agent infrastructure: if a framework can execute a workflow, teams assume it can govern a system. That assumption is wrong.
A workflow runtime can move work forward, but it cannot tell your product who owns the truth when that work pauses, fails, waits for approval, or resumes after interruption. In a demo, that gap is invisible. In production, it becomes the architecture. And it is exactly why so many promising agent systems feel deceptively complete right up until the moment they become operationally fragile.
Over the last few months, agent frameworks have made real progress. They can now handle multi-step execution, tool calling, retries, suspension, and even natural-language resumption with impressive elegance. Compared to the brittle prompt chains most teams were building a year ago, this is a huge step forward.
But execution is not governance.
That distinction is where most teams get into trouble. A workflow engine answers the question: can this process run? A control plane answers a very different one: can this process be trusted, observed, interrupted, resumed, audited, and understood across the entire system?
Those are not the same thing. And the more capable workflow frameworks become, the easier it is to confuse them.
Why the Demo Is So Convincing
The reason this illusion is so persistent is that modern workflow demos are genuinely impressive. The happy path now looks clean:
The agent starts a workflow.
The workflow calls a few tools.
It pauses for human input.
The next message resumes execution.
The run completes.
The UI shows a tidy success state.
If all you need is proof that the framework can orchestrate a sequence, that is enough. But a production system is not judged on its happy path. It is judged on everything around it:
What happens if the browser reloads while the workflow is suspended?
What state survives a worker restart?
How does the frontend know whether the system is running or merely quiet?
Which component is allowed to cancel or retry a run?
Where do approvals actually live?
How is partial progress represented?
Who resolves disagreement between runtime state, session state, and UI state?
A workflow runtime can help you execute steps. It does not automatically solve those questions. And those questions are where production architecture begins.
The Difference Between Execution and Control
A workflow is a mechanism for advancing work. A control plane is the layer that makes that work governable.
The workflow says:
Do step one.
Then step two.
If a condition is met, branch.
If human approval is needed, suspend.
If approval arrives, resume.
The control plane says:
Who is allowed to start this?
Who is allowed to resume it?
How should the system represent suspension to a user?
What counts as a failure?
When do we retry?
How do we recover after an interruption?
Which state is authoritative?
How do we propagate lifecycle changes across the UI, storage, and operational tooling?
That second list is where real systems live.
This is why so many teams feel an odd sense of disappointment after integrating a workflow framework. The framework works. The workflow runs. The demo succeeds. And yet the product still feels unfinished, brittle, or hard to reason about.
That is not because the workflow abstraction is bad. It is because the workflow abstraction is only one layer of the system.
Where the Control Plane Quietly Reappears
Most teams do not set out to build a control plane. They think they are adding a workflow engine and simplifying their stack. Then reality starts arriving in small, practical requests. Someone asks for:
A status API.
A cancel button.
A retry path.
A resumable approval flow.
A frontend progress indicator.
A persistent session view.
A recovery job for orphaned runs.
A way to distinguish “waiting” from “stuck.”
An audit trail for who approved what.
None of these requests sound like platform architecture in isolation. They sound like product polish. But together they form something much more significant. They form the control plane.
This is one of the most common patterns in AI systems today: teams begin with a workflow runtime, then slowly rebuild governance around it through helpers, wrappers, sync layers, metadata patches, event translators, and UI-specific logic.
The result is often a codebase full of “temporary” glue that no one planned, but everyone now depends on. That is not accidental complexity. It is the system trying to restore missing control.
The Real Problem Is Not Workflow Logic. It Is Contract Drift.
When people talk about agent orchestration problems, they often focus on the runtime. But the hardest failures rarely come from step sequencing itself. They come from disagreement between layers.
The runtime thinks the workflow is suspended.
The memory layer has stored the tool call.
The backend session says the run is active.
The frontend expects a different event shape.
The user sees no approval UI and assumes the system is broken.
Nothing has technically crashed. No single component is “wrong.” And yet the product has failed.
This is what makes agent systems so slippery to debug. They often break not because intelligence failed, but because the system’s contracts drifted apart. One layer speaks in workflow runs. Another speaks in messages. Another speaks in tool states. Another speaks in UI statuses. Another stores session metadata that lingers long after the runtime has moved on.
If those languages are not explicitly reconciled, you do not get resilience. You get coincidence.
This is the point where many teams realize that the real problem was never simply “how do we execute a workflow?” It was always “how do we keep the entire product aligned around what that workflow means?”
The Frontend Is Where the Illusion Collapses
If you want to know whether your agent architecture is real, do not look at the workflow trace. Look at the frontend.
Can the UI tell the difference between: running, suspended, awaiting approval, partially completed, failed, resumed, and silently abandoned? Can it reconstruct those states after a reload? Can it show the user the next valid action without inventing information? Can it do that from persisted history, not just from live streaming events?
This is where a lot of supposedly mature agent systems fall apart. They have beautiful backend orchestration and terrible state legibility. The workflow may be alive, but the product cannot explain what is happening in a trustworthy way.
That is not a frontend bug. That is an architecture failure. A system is not governable if only the runtime understands its state.
Why Native Framework Features Still Matter
None of this is an argument against workflow frameworks. Quite the opposite.
Native workflow primitives are one of the most important upgrades in the agent stack. They reduce custom orchestration code, create a shared model for multi-step execution, and make suspension and resume dramatically easier to reason about than ad hoc prompt choreography.
That is real progress. But frameworks should be understood as execution substrates, not as complete operating models for autonomous systems.
They help you answer:
How does work proceed?
How does a process pause?
How does it resume?
How do steps compose?
They do not automatically answer:
What is the source of truth?
What does the product show the user?
What survives interruption?
How is governance enforced?
Where does policy live?
How is the system debugged?
Who is allowed to intervene?
If you treat workflow primitives as the entire architecture, you will eventually rebuild the missing parts in less coherent ways.
What a Real Control Plane Must Own
A real control plane does not need to be a giant internal platform on day one. But it does need to make a few things explicit:
State Ownership: Which layer is authoritative for execution state, product state, and user-visible state?
Lifecycle Authority: Who can start, pause, resume, cancel, retry, and restart work?
Interruption Semantics: What happens after reload, reconnect, process restart, or partial failure?
Human Checkpoints: Where do approvals live, and how are they represented consistently across runtime, storage, and UI?
Translation: How do internal workflow events become operational signals and user-facing status?
Policy: What may run automatically, under which conditions, and with what boundaries?
Observability: How do you tell the difference between activity, waiting, failure, and deadlock?
These concerns are not beyond the workflow. They are the architecture around the workflow. That is what a control plane exists to hold together.
The Better Mental Model
The cleanest way to think about this is simple:
A workflow runtime is an execution engine.
A control plane is a governance layer.
The engine moves work. The control plane makes work safe, recoverable, visible, and operable. You need both.
Without the engine, you have manual orchestration and brittle logic. Without the control plane, you have automation that can run but cannot be trusted.
That is the workflow illusion: the belief that once a framework can execute a sequence, the hard part is over. In reality, the hard part is just becoming visible. Because production systems are not defined by whether work can continue. They are defined by whether the system can still tell the truth while that work is in motion.
If you are building with agents today, that is the design question that matters most. Not whether your workflow runs. But whether your architecture can govern it once it does.
Flurit is what I’m building to make agentic DevOps safe by design where identity, policy, and execution boundaries are first-class, not afterthoughts.
ou are right that execution is not control
But there is a deeper gap
The problem is not only that systems lack a control plane
It is that the conditions of decision are never made visible to the user at the moment they act
This is not a technical limitation
It is a structural omission
And as long as that layer is missing
control will remain partial
and responsibility will stay blurred
The workflow illusion is real and expensive when it lands in production. Getting the agent to run is the easy part.
The harder question is whether the workflow around it was designed to be trusted at scale: bounded sequencing, live state checks, escalation triggers defined before go-live, not discovered through incidents. Execution without those foundations just fails faster.