

Your Agent Needs Receipts, Not Memory
Long-horizon agents need evidence they can recover, verify, and invalidate, not every past token stuffed into context.

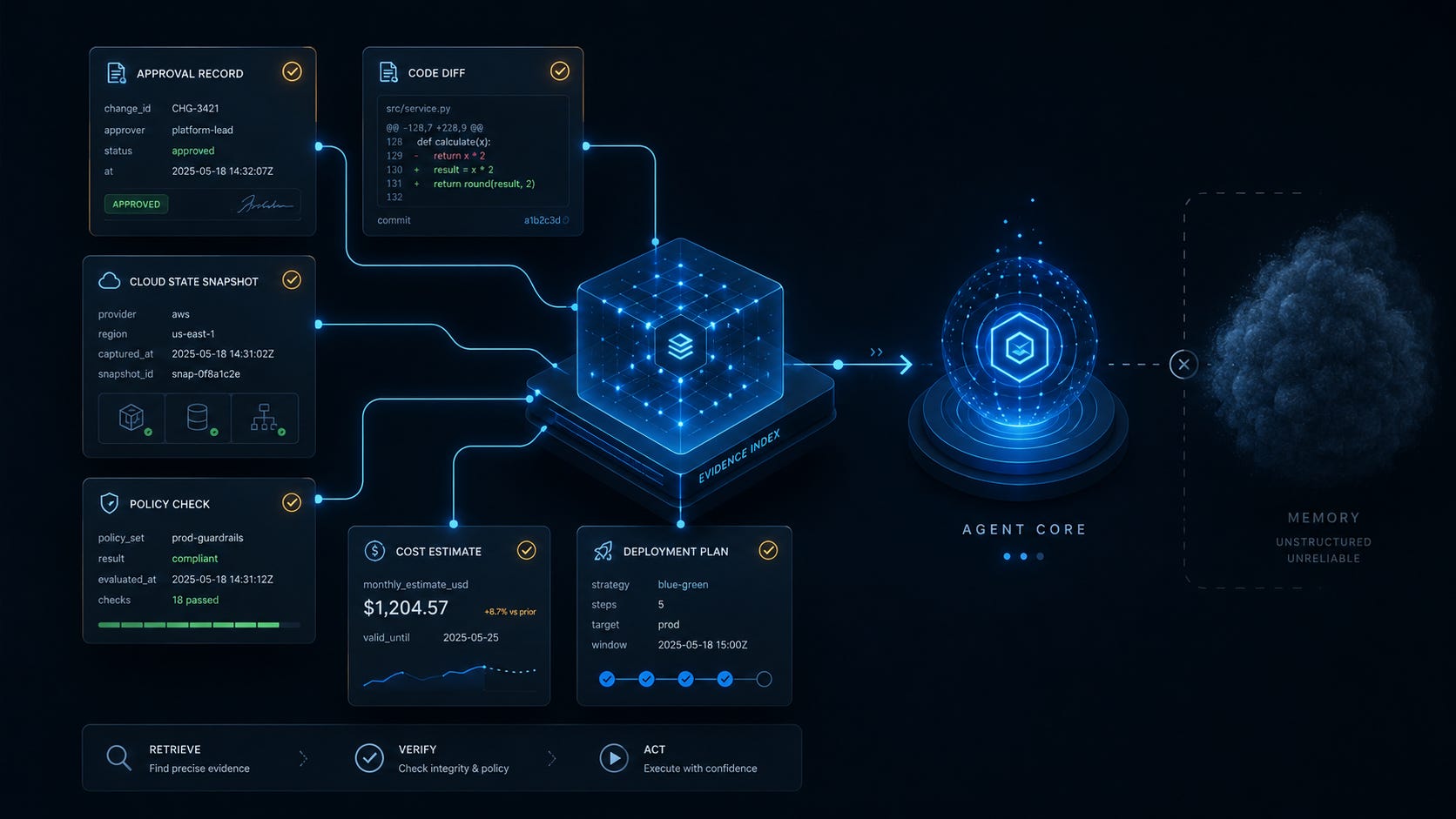
Your agent says the plan was approved.
Production does not care.
Production wants to know who approved it, what changed since then, which commit it was based on, which policy version passed, and whether the approval still applies.
This is the gap between memory and evidence.
Most agent systems are still designed to help the model remember enough to continue. Production systems need something stricter: they need the agent to recover the exact evidence behind its next action.
A longer context window helps. But it does not solve this problem by itself.
The future agent does not need to remember everything.
It needs receipts.
The problem is not only context length
Most conversations about agent memory still start with the same limitation: the context window is finite.
That is true.
As agent tasks get longer, the model cannot keep every tool result, file diff, decision, error, approval, and intermediate observation in the active prompt. The obvious answer is to compress, summarize, truncate, or retrieve.
But the more interesting problem is not only size.
It is evidence.
When an agent compresses history into a summary, something is lost. Maybe the summary is good enough. Maybe it misses the one detail that matters later. Maybe it turns a precise tool output into a vague statement. Maybe it remembers that something was approved, but not who approved it, for what scope, and under which version of the plan.
That is fine for casual chat.
It is not fine for production workflows.
A DevOps agent cannot simply “remember” that the infrastructure looked safe.
It may need the exact Terraform diff, the exact cloud snapshot, the exact policy result, the exact cost estimate, and the exact approval event.
Not always.
But when the workflow reaches a risky step, the agent needs a way to recover the evidence.
This is why I think the next memory layer for agents will not be only about making context bigger.
It will be about making context referential.
Summaries are useful, but they are not receipts
Summaries are the default escape hatch.
When the context gets too long, summarize the previous steps. Keep the important parts. Drop the rest. Continue.
This works until the agent needs to prove, compare, audit, or reverse something.
A summary can say:
The deployment plan was reviewed and approved.
But production systems often need more than that.
Reviewed by whom?
Approved for which environment?
Based on which repository commit?
Against which cloud state?
With which policy checks?
Was the approval still valid when execution started?
Was the plan regenerated after the approval?
If the summary cannot point back to the original evidence, it becomes a weak memory.
It tells the agent what to believe.
It does not let the agent verify why that belief is still valid.
That distinction matters.
The more agency we give systems, the less comfortable we should be with memory that cannot produce receipts.
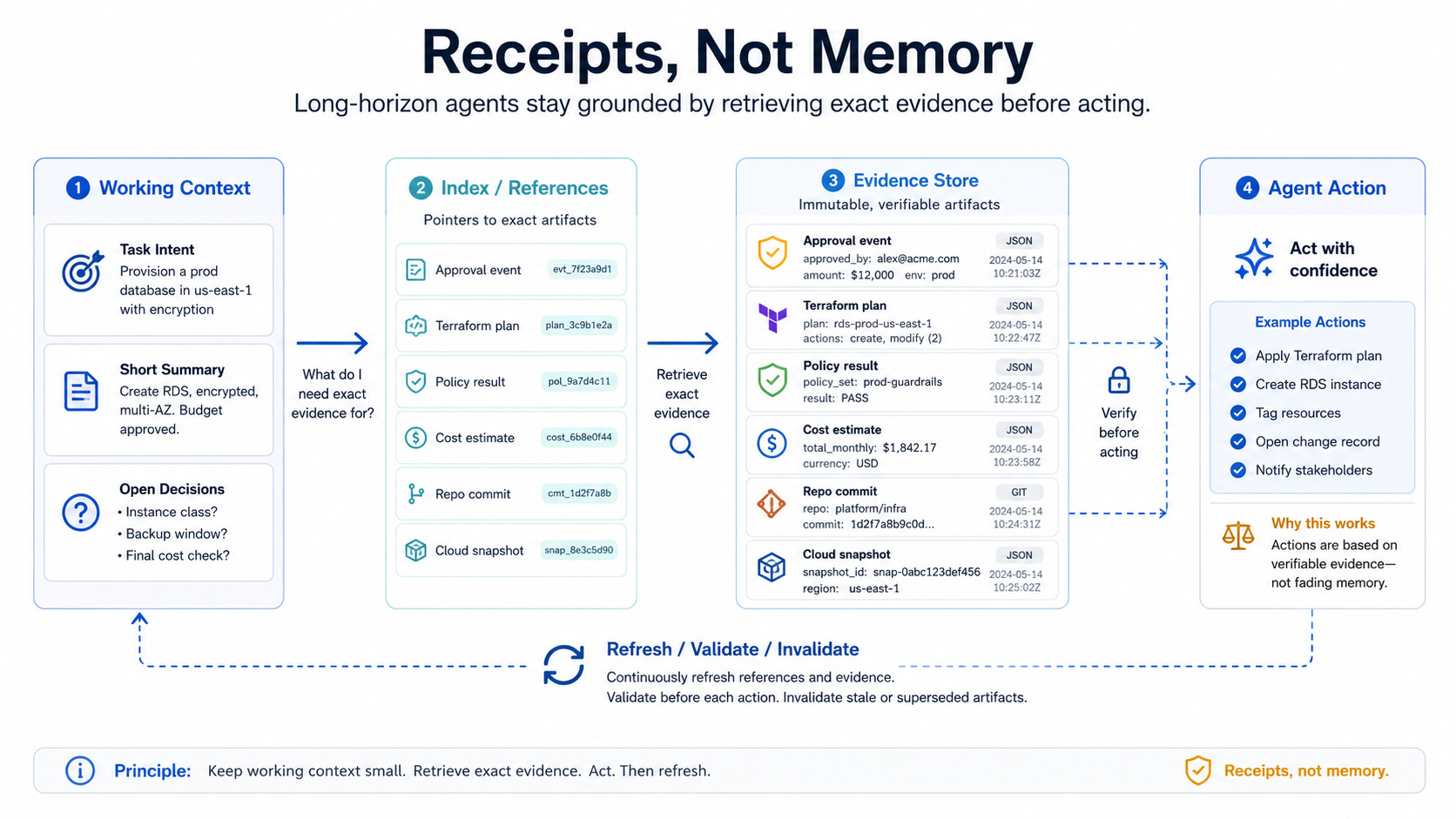
Indexed memory is a better mental model
A useful recent research direction is indexed experience memory.
In the paper Memex(RL): Scaling Long-Horizon LLM Agents via Indexed Experience Memory, the authors frame the core problem clearly: long-horizon agents are bottlenecked by finite context windows, and truncation or running summaries are lossy because they compress or discard past evidence. Memex keeps a compact working context made of structured summaries and stable indices, while storing full-fidelity interactions in an external experience database. The agent can then dereference an index when it needs the exact past evidence again.
That is the shift I find important.
The working context does not need to carry everything.
It needs to carry enough structure to know what exists and when to retrieve it.
In simple terms:
Context window:
Compact summaries + stable references
External memory:
Full-fidelity evidence + interaction history
Agent behavior:
Know when to retrieve the exact record
That turns the context window into something closer to an index.
Not a dumping ground.
Not a compressed diary.
Not a bag of vaguely relevant chunks.
An index.
A working map of the evidence that exists outside the active prompt.
Why this matters for agents that act
For agents that only answer questions, summary-level memory may be enough in many cases.
For agents that act, it is not.
An action depends on state.
And state changes.
This is especially true in DevOps and infrastructure workflows.
An agent may scan a repository, infer infrastructure requirements, generate a blueprint, estimate cost, check policy, create Terraform, open a pull request, wait for approval, and then continue later.
Between those steps, reality may change.
The repository may get a new commit.
The cloud state may drift.
A policy may be updated.
The cost estimate may become stale.
The user may change the target environment.
Another engineer may merge a conflicting change.
If the agent only carries a summary, it may continue with confidence.
If it carries indices, it can re-open the exact evidence, compare it with the current state, and decide whether the workflow is still valid.
That is the difference between memory as convenience and memory as operational infrastructure.
The context window should carry pointers, not everything
A production agent’s active context should probably contain fewer raw details and more structured references.
For example, instead of keeping a large Terraform plan in context forever, the agent should keep a compact reference:
terraform_plan:v3
source_commit:abc123
generated_at:2026-06-03T10:42
policy_result:passed_with_warning
cost_estimate:estimate_782
approval:pending
The full plan, policy result, cost estimate, and approval event should live outside the context window in a retrievable store.
When the agent needs them, it dereferences the pointer.
When the agent reaches an execution step, it refreshes the current state and checks whether the referenced evidence is still valid.
This sounds less magical than “infinite context.”
But it is closer to how production systems work.
Databases do not put every row into application memory.
Operating systems do not keep every file loaded into RAM.
Distributed systems do not trust old state forever.
They use references, handles, caches, invalidation, and durable stores.
Agents will need the same discipline.
Long context does not remove the need for memory architecture
There is a tempting counterargument:
What if models just keep getting larger context windows?
They will.
That will help.
But larger context windows do not remove the need for memory architecture.
They may even make the problem easier to ignore.
A large context window can hold more information, but it does not automatically know what is evidence, what is stale, what was superseded, what requires verification, or what should be retrieved exactly instead of remembered approximately.
Recent memory benchmarks also suggest that simply having access to long context is not enough. LongMINT, a 2026 benchmark for long-horizon memory under interference, evaluates systems across contexts averaging 138.8k tokens and extending up to 1.8M tokens. Across representative systems including long-context LLMs, RAG, and memory-augmented agents, average accuracy was only 27.9%, with particular weakness in questions requiring aggregation across multiple pieces of evidence and in handling earlier facts revised by later updates.
That result matters because real workflows are full of interference.
Facts get updated.
Plans get revised.
Approvals expire.
Policies change.
Commits supersede earlier commits.
Cost estimates become stale.
Deployment states drift.
In that world, the problem is not just remembering more.
The problem is remembering correctly under change.
Memory needs invalidation
This is the part I think will become more important.
Agent memory should not only have retrieval.
It should have invalidation.
A memory item should be able to expire, be superseded, be marked risky, require refresh, or become unusable for certain actions.
For example:
A repository scan should expire when the commit changes.
A cloud snapshot should expire when drift is detected.
A cost estimate should expire when resource parameters change.
An approval should expire when the plan changes.
A policy result should expire when the policy version changes.
A skill recommendation should expire when a better validated skill exists.
Without invalidation, memory becomes a liability.
The agent may remember something accurately and still use it incorrectly because the world has changed.
This is why I do not like the phrase “agent memory” when it is used too casually.
Memory is not only storage.
Memory is lifecycle.
Write.
Index.
Retrieve.
Validate.
Refresh.
Invalidate.
Archive.
That is the architecture.
The future memory layer will look more like an evidence system
For long-horizon agents, I think the memory layer will need at least four qualities.
First, it must be referential. The agent should carry stable pointers to exact evidence, not only summaries.
Second, it must be structured. The system should know whether a memory item is a file, tool result, approval, policy check, cost estimate, trace, plan, or user decision.
Third, it must be validatable. The agent should know when the evidence must be refreshed before action.
Fourth, it must be auditable. If an agent made a decision based on memory, the system should be able to show which memory it used and what exact evidence was recovered.
That is different from chat history.
It is different from RAG.
It is different from dumping more text into the prompt.
It is closer to an evidence system for agentic execution.
Why this matters for DevOps agents
DevOps agents will expose this problem early because they operate across moving systems.
They do not only need to remember what the user asked.
They need to remember and verify:
Which repo was scanned.
Which commit was used.
Which infra drivers were detected.
Which blueprint was generated.
Which Terraform version was created.
Which policy checks passed.
Which cost estimate was shown.
Which approval was granted.
Which environment was targeted.
Which cloud state was current at the time.
Which rollback path was available.
If the agent cannot recover this evidence, the workflow becomes hard to trust.
If it cannot invalidate stale evidence, the workflow becomes unsafe.
This is why I think “longer context” is the wrong product promise for DevOps agents.
The better promise is:
Every important decision can point back to the exact evidence that made it valid.
That is what serious users will eventually need.
Not because they love audit trails.
Because production workflows break when agents act on stale or unverifiable assumptions.
The context window becomes a working set
The more I think about it, the more the context window starts to look like a working set.
It should contain what the agent needs right now:
Current task intent.
Relevant constraints.
Fresh state.
Short summaries.
Pointers to evidence.
Open decisions.
Next actions.
Everything else should live in an indexed memory layer.
The agent should be able to pull exact records back into context when needed, then drop them when they are no longer useful.
This is not as exciting as saying “one million token context.”
But it is a better design pattern.
A larger context window gives the agent more room.
An indexed memory system gives the agent better discipline.
And long-horizon work needs discipline more than space.
Closing thought
The future of agent memory will not be about remembering everything.
It will be about knowing what to keep active, what to summarize, what to index, what to retrieve exactly, and what to invalidate.
That is why I think the context window is becoming an index.
For short conversations, context can be a container.
For long-running agents, context has to become a map.
A map of evidence.
A map of decisions.
A map of state that may have changed.
The agents that matter in production will not be the ones with the longest memory.
They will be the ones that know when memory is not enough and evidence must be recovered.
P.S. This is also one of the ideas shaping how we are thinking about Flurit AI. DevOps agents should not only remember previous steps. They should preserve evidence across repo scans, blueprints, Terraform plans, policy checks, cost estimates, approvals, and deployment decisions.
If that sounds relevant to your team, you can join the early-access waitlist here: [Join the Flurit waitlist]
receipts over memory makes sense for agent reliability. harder question on the team side is who decides what context the agent keeps between sessions - nobody seems to own that call.
"But production systems often need more than that." Each system has different needs and hence the struggles